DALL-E 2. Sztuczna inteligencja tworząca sztukę, grafiki, zdjęcia

Jak to jest być jedną z pierwszych osób, mających dostęp do testów najbardziej zaawansowanej sztucznej inteligencji, potrafiącej tworzyć sztukę? Absolutnie wspaniale :). Jakby się mnie zapytać 3 lata temu, kiedy będzie można w miarę swobodnie rozmawiać, ze sztuczną inteligencją, albo kiedy zacznie ona tworzyć własne dzieła, to powiedziałbym, że może w okolicach 2040 roku. Zapytany o to samo dzisiaj, nie musiałbym zgadywać – odpowiedź jest oczywista i brzmi: przecież A.I. już jest na tym etapie, tyle że póki co w wersji beta.
Ten artykuł napisałem w momencie rozpoczęcia zamkniętych beta testów DALL-E 2, natomiast później go wielokrotnie aktualizowałem. Ostatnia aktualizacja: Grudzień 2022.
Napisałem też kontynuację dot. najnowszego Midjourney: Midjourney w 2023 roku – Sztuczna inteligencja do generowania grafik: poradnik, konfiguracja, prompty itd.



DALL-E 2 to najbardziej zaawansowana, "artystyczna", sztuczna inteligencja. Wygenerowała dla mnie wszystkie grafiki i "zdjęcia" w tym wpisie (oczywiście wg. moich wytycznych). Nie należy mylić DALL-E 2 od OpenAI z DALL-E mini, zrobionym przez Crayion. To drugie jest prostym A.I; nie mającym nic wspólnego z oryginałem.


Jak się DALL-E 2 spisuje w różnych zastosowaniach, jakie ma ograniczenia, jak wyprzedziłem kilka milionów osób w kolejce do bety – o tym wszystkim za chwilę się rozpiszę. Ale na wstępie doprecyzuję, że to nie są fotomontaże, ani przerobione zdjęcia i grafiki, które ktoś wcześniej stworzył. Wszystko zostało zrobione od zera, na potrzeby tego artykułu.


I tak jak sto osób poproszonych o stworzenie tej samej rzeczy, da sto innych rezultatów, tak samo jeśli sto razy zapytamy sztuczną inteligencję o to samo, to otrzymamy za każdym razem co innego (chociaż najpewniej wciąż zgodnego z opisem).

Nie przegap dodatkowych materiałów!
Szykuję podobne publikacje o najlepszych A.I. które obecnie się pojawiają. Zarówno o tych stricte do zdjęć, jak i do grafik. Będzie nawet artykuł o najlepszym A.I. do upscalowania plików graficznych, z licznymi przykładami jak mogą wyglądać obrazy z DALL-E, powiększone do 4K.
Nadchodzi też publikacja o fotorealizmie w Midjourney. Dodatkowo pokażę na żywo, jak korzystam z A.I. i przygotuję listę najbardziej przydatnych narzędzi, opartych o sztuczną inteligencję. Zostaw maila i dam ci o tym znać.
Wcześniejsze przykłady przypominają zdjęcia, ale mogę zechcieć czegoś bardziej w stylu digital art:



Może to być niemal cokolwiek przyjdzie mi do głowy, łącznie z najróżniejszymi stylami malarskimi. Zresztą w dalszej części pokazuję, jakby wyglądały backstage sesji zdjęciowych, jako obrazy w stylu Pisassa, Rembrandta itd. Żeby zademonstrować jakie są możliwości, nie wrzucam samych fotorealistycznych obrazków, tylko najróżniejsze.



Zaprezentowanie możliwości DALL-E 2 bardzo nasiliło dyskusje o tym, jak A.I. wpłynie na naszą twórczość.
Zagłada dla grafików i fotografów?
W różnych zawodach kreatywnych zaczęto obawiać się, czy A.I. nie przejmie ich pracy już w najbliższych latach (a przecież jeszcze niedawno myślano, że to właśnie takie zawody przetrwają najdłużej). Czy ilustrator dalej będzie potrzebny, jeśli autor książki może wydać to samo polecenie A.I? Co z pozostałymi grafikami – chociażby z concept artystami. Czy znikną niektóre specjalizacje fotograficzne itd. W ostatnich dniach jestem o to pytany zewsząd.



Gdy kumpel poprosił mnie o wygenerowanie kilku "zdjęć", to po zobaczeniu efektów napisał: "Oni zarobią na tym miliardy. Wysadzą w kosmos fotografów". I jeśli chodzi np. o tych specjalizujących się w zdjęciach stockowych, bez dwóch zdań potrzeba na ich usługi zmaleje drastycznie. Szukając portretowego zdjęcia dalmatyńczyka, na czarnym tle; albo "spoko wyglądającego kota", w okularach i skórzanej kurtce, mogę rozpocząć poszukiwania na stockach, lub po prostu powiedzieć sztucznej inteligencji, czego szukam i po kilku sekundach mieć temat z głowy:


Poza tym stocki pewnie będą działać w przyszłości inaczej. To m.in na nich będziemy mogli generować zdjęcia przy użyciu A.I; wskazywać, co chcemy zmienić w tych, które sobie upatrzyliśmy itd.


Lookbooki to proste zdjęcia do katalogów, najczęściej na jednolitym tle – robione w ogromnych ilościach. W Chinach normą jest, że modelka zmienia stylizację kilka razy w ciągu minuty i tak przez cały dzień. Takie fotografie też na pewno kiedyś się będzie robić wirtualnie, ale jeszcze miesiąc temu byłem przekonany, że przy użyciu fotorealistycznych avatarów i technologii 3D. Teraz widzę, że spokojnie można by wytrenować A.I; by robić to setki razy szybciej, w dwóch wymiarach. Bo bądźmy szczerzy – ten typ fotografii niewiele różni się od pracy na taśmie produkcyjnej i aż się prosi o zautomatyzowanie. Natomiast w większości dziedzin fotografii, chodzi o upamiętnienie czegoś z rzeczywistości, dlatego myślę, że rozwój A.I. tam nie namiesza zbytnio, a jeśli już, to po to, by dać fotografom większe możliwości.
Zresztą już teraz inne A.I. bardzo pomagają przy zdjęciach. Topaz Photo AI potrafi odzyskać twarze z fotografii, na których nie ma ostrości, zwiększa rozdzielczość i odszumia wręcz ekstremalnie zaszumione fotki. Na poniższej fotce autofocus nie trafił, ale użyłem Topaza i taki jest rezultat:
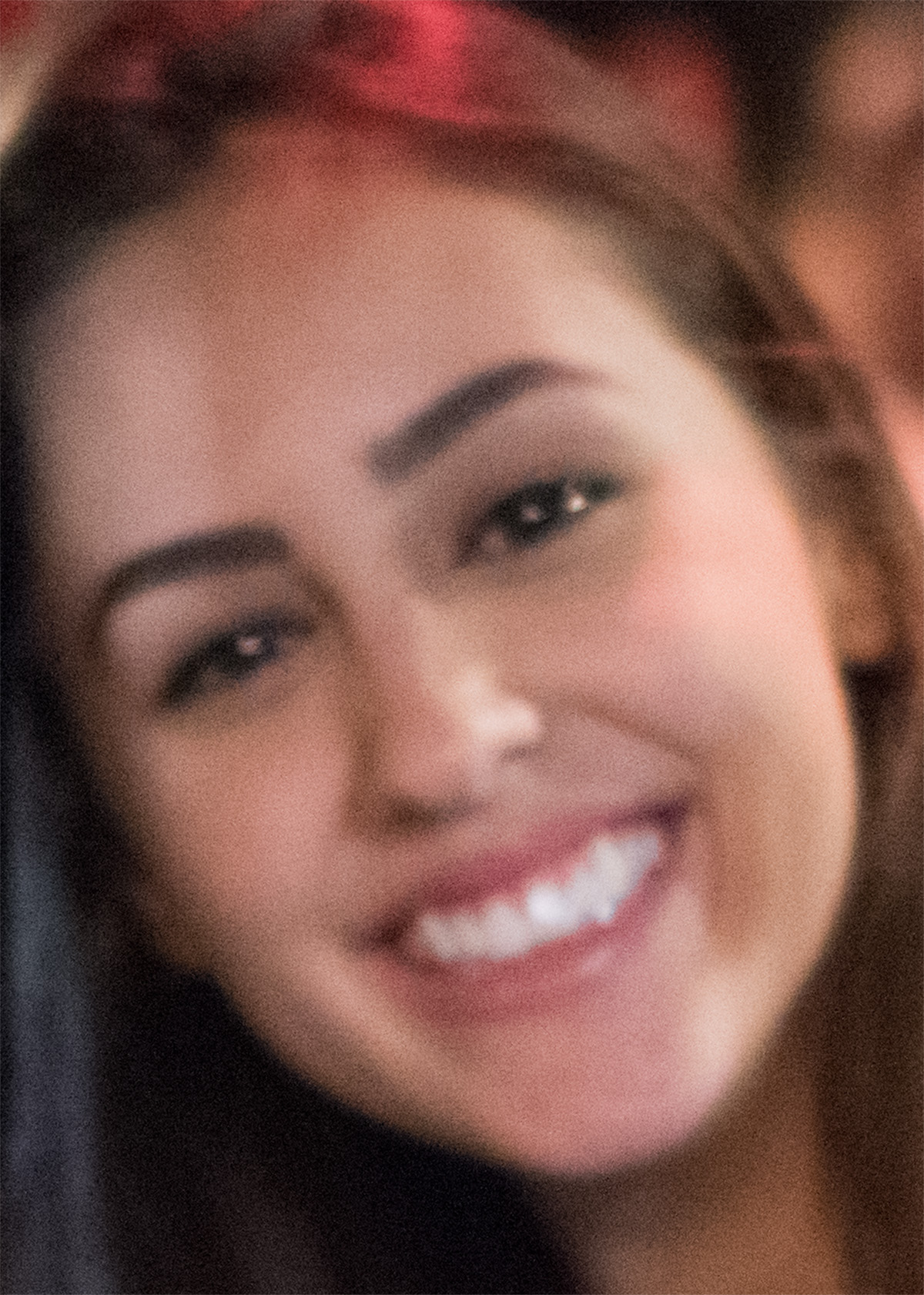
Ten i mnóstwo innych zrobionych przeze mnie przykładów można zobaczyć w artykule: Topaz Photo AI – Sztuczna inteligencja do ratowania zdjęć: powiększanie, wyostrzanie i odszumianie. Co ważne, jest to program z bardzo prostym interfejsem, działający w dużej mierze automatycznie, co wcale nie jest takie oczywiste, bo obecnie wiele AI to projekty, które nie miały styczności z żadnym designerem, jedynie z programistami.
Jak mocno poprawić jakość grafik z DALL-E i innych AI
W tym wpisie wszystkie grafiki z DALL-E 2 zamieszczam bez modyfikacji, czyli rozdzielczość to prehistoryczne 1024x1024 px. Natomiast fotografowie wiedzą, że jedną z funkcji wyżej wspomnianego Topaz Photo AI, jest upscalowanie zdjęć i grafiki. Można go więc użyć do poprawiania rozdzielczości tego co generuje DALL-E. Jednak jeśli inteligentne wyostrzanie, to jedyna potrzebna funkcja, to Topaz ma coś jeszcze, a przy okazji jest dużo tańsze. Mowa o programie Topaz Gigapixel AI. Jeśli ktoś na poważnie myśli o używaniu grafik generowanych w Midjourney, Stable Diffusion, DALL-E 2 itd; to Gigapixel lub Photo AI będzie ogromnym upgradem jakości:


Oczywiście nie zawsze rezultaty będą rewelacyjne, ale najlepsze jakie są obecnie możliwe, bo Topaz ma najlepsze upscalowanie, jakie aktualnie istnieje.
AI pomaga fotografom
Jeszcze bardzo szybki, ale ciekawy offtopic… Taki efekt uzyskałem jednym kliknięciem myszki, dzięki sztucznej inteligencji Retouch4me:

To pierwsze AI potrafiące uzyskiwać efekty, jak od zawodowego retuszera. Bez kiczu i rozmywania skóry, znanego z wszystkich innych programów do "poprawiania" skóry. O tym też napisałem artykuł z wieloma przykładami "przed i po": Retouch4me: Automatyczna obróbka zdjęć, przez sztuczną inteligencję. Dlatego uważam, że na obecnym etapie, AI zapewnia ogromną pomoc fotografom.
Jednak zostawmy już zdjęcia i wróćmy do generowania grafik…
AI vs. praca

Zawodowym grafikom sztuczna inteligencja może nie tyle zabrać pracę (chociaż części z nich pewnie tak), co ją niesamowicie uprościć i przyspieszyć. Mając w głowie koncept, zrobienie pierwszej wersji przy użyciu A.I. zajmie minimum 100 razy mniej czasu, niż wykonanie tego klasycznie. Mógłbym przetestować wielokrotnie więcej pomysłów i w efekcie stworzyć coś lepiej lub szybciej. Potrzeba na fajne pomysły nie zniknie, a nikt nie płaci grubej kasy za concepty przez to, że dobrze wyglądają, tylko przez to, że są… pomysłowe, rozwiązują różne problemy, wyciskają max możliwości silnika graficznego, w jakim zostaną wykorzystane itd. A.I. w przyszłości i w tym będzie znakomite, jak i we wszystkim innym, ale to zbyt odległa przyszłość, by był sens ją teraz rozważać.
Stworzenie 6 wariantów tego co chcę, zajmuje mi w DALL-E obecnie 5-10 sekund i za każdym razem otrzymuję właśnie 6 propozycji 4 propozycje (ponieważ zmniejszono ich liczbę w aktualnej wersji DALL-E). Możliwości są większe, bo można robić warianty… wariantów oraz je edytować, ale o tym później. Świecące grzyby w naturalnym środowisku, z dymem w kadrze? Kilka sekund później:






Postęp jaki został poczyniony ze sztuczną inteligencją przez ostatnie 3 lata, jest niewyobrażalny. Jednak nie śledząc tematu, łatwo nie zdawać sobie z tego sprawy. W końcu boty na większości stron wciąż są głupie jak but, podobnie jak asystenci głosowi w naszych telefonach. Natomiast istnieją też twory takie jak GPT-3, czyli moim zdaniem najbardziej zaawansowane A.I. przy którym Siri i Alexa wydają się pochodzić z epoki sprzed wynalezienia koła.



Musiałbym naprawdę długo konwersować z GPT-3, żeby się zorientować, że to nie człowiek. DALL-E jest oparte właśnie o GPT-3. Jednak w wersji sprzed roku nie robiło wielkiego wrażenia. Dopiero niedawno zaprezentowano wyniki z wersji 2 i internet eksplodował – nawet media kompletnie niezwiązane z A.I. rozpisywały się o tym. Przy okazji mnóstwo osób zaczęło pokazywać grafiki robione przez DALL·E mini, jednak jak już wspomniałem we wstępie, to zupełnie inny, mały projekt, nie mający nic wspólnego z oryginałem, co zresztą widać po jego wynikach. Po prostu za sprawą nazwy, leci na popularności oryginału. W tym artykule skupiam się konkretnie na DALL-E 2.



To wciąż wczesny etap rozwoju – grafiki mają różne artefakty, niektóre elementy nie są spójne itd. Jest możliwość poprawienia wybranych fragmentów, aczkolwiek nie robiłem tego w grafikach, które wybrałem do artykułu. Jednak wyobraźcie sobie, jak będzie wyglądać finalna wersja, jeśli zupełne początki beta testów, dają takie rezultaty.



Artyści testują DALL-E 2
Miałem zdradzić jakim cudem mimo tylu milionów osób zgłoszonych do bety, znalazłem się w niej już na starcie. To ze względu na to, że zajmuję się fotografią, grafiką 3D i concept artem. Nie liczyła się kolejność zgłoszeń, tylko właśnie uzdolnienia artystyczne. Musiałem też wziąć udział w spotkaniu, na którym tłumaczono wszystkie sprawy związane z DALL-E i można było wypytać o różne kwestie. Np. dlaczego w becie nie da się generować nagich postaci? Ponieważ nie ma jeszcze pewności, czy DALL-E zawsze potrafi rozróżniać dorosłych od dzieci. Niby potrafi, no ale jeśli raz by się pomyliło, byłby ogromny problem.


Początkowo nie do końca rozumiałem, czemu OpenAI tak zależało, by zacząć właśnie od artystów. Teraz, po dziesiątkach godzin spędzonych z DALL-E i na Discordzie dla beta testerów, wszystko jest jasne. Pierwsza kwestia jest oczywista – kreatywność, a więc tworzenie obrazów, z którymi być może A.I. będzie mieć początkowo problemy. Jednak wybrano nas też najpewniej przez to, że znamy różnice między ogniskowymi, czasami naświetlania, oświetleniem, silnikami renderującymi, stylami graficznymi i stylami różnych artystów, potrafimy określić kompozycję kadrów itd. Mamy w głowach określony efekt finalny i potrafimy bardzo dokładnie go opisać. Uwzględniamy to wszystko w komendach wydawanych DALL-E. Sprawdzamy jakie parametry działają najlepiej i wychodzą nam coraz lepsze rezultaty.

Wśród testerów są też osoby nieznające się na fotografii, nierozumiejące w jaki sposób na wygląd zdjęcia wpływa wartość przysłony, czas naświetlania, jak się deformują np. postacie w zależności od odległości od obiektywu itd. Z pewnością jest im znacznie ciężej uzyskiwać przewidywalne rezultaty, ale starają się dopytywać na Discordzie o podstawy, bo tak na prawdę one wystarczają.


Z drugiej strony, widziałem mnóstwo conceptów sneakersów zrobionych DALL-E, ale ponieważ o butach wiem tyle co nic, to nie potrafiłbym wyjaśnić A.I. jak wyglądają te, które sobie właśnie wyobraziłem. Także przydaje się jak najszersza wiedza o wszystkim, co się chce zrobić.

Otóż OpenAI, czyli twórcy GPT-3 i DALL-E, nie wiedzą w jaki sposób jest się najlepiej zwracać do ich AI. To sztuczna inteligencja, więc nie ma zaprogramowanych konkretnych komend, po prostu reaguje na polecenia tak, jak uważa, że będzie najlepiej. Czym bardziej precyzyjne polecenie, tym rezultat (zazwyczaj) bliższy oczekiwaniom. Postać może być w najróżniejszym wieku, różnej płci, zaprezentowana w różnym stylu. Budynek może być widoczny o różnej porze dnia, z różnym światłem, mieć różne kolory itd; więc dobrze jest to wszystko określić. Wpisuję więc "photo of slim girl, 20yo, close-up, high detail, studio, smoke, sharp, pink violet light, studio, 85mm sigma art lens" i wynik zaskoczy mnie o wiele mniej, niż gdybym dał krótszy opis:




Ale mogę pójść znacznie dalej… Photo of robot with 20yo girl inside, LEDs visor helmet, profile pose, bust shot, high detail, studio, black background, smoke, sharp, cyberpunk, 85mm Sigma Art lens:






Lub coś prostszego, z zupełnie innej parafii: cyberpunk church, high detail, smoke, sharp, neon lights, neon cross:



Natomiast poniżej chciałem "photo of dark temple, golden treasure, high detail, smoke, sharp, fog:

I jeszcze coś bardziej przyziemnego – "House on fire at night, high detail, smoke, sharp, fog, darkness":

A.I. w służbie sesjom zdjęciowym
Na liście sesji zdjęciowych, które miałem w planach, są portrety z kotami ubranymi w naszyjnik i koronę. Ale w sumie nie wiem czy wolałbym klasycznego kota, czy Sphinxa. No więc proszę DALL-E o zdjęcia obu i może mi to ułatwi decyzję:






Nie doprecyzowałem obiektywu, więc sphinx na czarnym tle wyszedł karykaturalnie, przez szeroki kąt.
Jestę instagramerę
Oczywiście mógłbym też poprosić o zwykłe zdjęcia kociaków, by podbić social media:



A skoro już jesteśmy przy zdobywaniu sławy na portalach społecznościowych… Hej DALL-E, "wygeneruj mi zdjęcie wymyślnego śniadania na Instagrama":


Innym razem wzięło sobie do serca słowo "Instagram", bo stworzone grafiki zamiast neutralnych kolorów, od razu miały nałożone filtry:




A może zdjęcie sernika? Jeszcze nigdy bycie influencerem nie było takie proste…



Backstage sesji, malowane w stylu znanych artystów
DALLE-2 rozpoznaje różne style malarskie (i nie tylko). Zobaczmy więc jakby wyglądały backstage sesji zdjęciowych, jako fanfiki (fanficki?) największych malarzy:
Rembrandt:



Rubens:



Picasso:



Pollock:



Vincent van Gogh:



Monet:



Salvador Dalí:



Warhol:



Jest dużo dyskusji na temat legalności takich grafik, bo mogą powstawać również na bazie styli żyjących artystów. Obecnie prawo nie nadąża za tym tematem, a np. Stable Diffusion A.I. wycofało opcję bazowania stylu na konkretnym autorze.
Przerabianie własnych grafik
Zamiast generować obrazy od zera, można wgrać coś swojego i powiedzieć DALL-E, co ma z tym zrobić. Niestety kompletnie nie potrafię rysować, ale z 3D sobie radzę, więc załadowałem do DALL-E render robota, którego zaprojektowałem w zeszłym roku:

Wgrałem powyższy plik i bez wpisywania jakichkolwiek komend kliknąłem, że chcę zobaczyć jego inne warianty. Oto niektóre z propozycji, jakie dostałem:



Niestety szczegółowość jest dużo niższa niż oryginału i niż większości "zdjęć" wygenerowanych od zera. Jest dużo artefaktów, bo DALL-E póki co niezbyt dobrze sobie radzi z łączeniem mechanicznych części tak, by miały sens. Natomiast drugi wariant zachowuje spójność kształtów z oryginałem i sugeruje, jak inaczej mógłbym przytwierdzić ręce do korpusu. Na bazie zaproponowanej głowy też byłbym w stanie zrobić coś ciekawego. Z kolei głowa pierwszej propozycji zainspirowała mnie do stworzenia zupełnie nowego projektu. Myślę że jako pomoc w grafice koncepcyjnej, DALL-E może znaleźć zastosowanie, potwierdza to też wiele osób z tej branży.
A sprawdźmy jak sobie poradzi ze zbliżeniem na dłoń. W lewym górnym rogu jest oryginał, a reszta to warianty, zaproponowane przez A.I:

Oczekiwałem dłoni, tyle że zmienionej, a dostałem zupełnie inne elementy. Ale co gdybym powiedział DALLiemu, by stworzył robota od zera? Zechciałem białego, humanoidalnego robota, z niektórymi częściami czerwonymi, bogatego w detale:



Dużo lepiej. Biorąc pod uwagę, że można sobie wygenerować setki wariantów, to są duże szanse, że na wielu pojawią się fajne rozwiązania.
Przerabianie własnych zdjęć
Niestety w becie nie można wgrywać zdjęć z realistycznymi twarzami. Biorąc pod uwagę, że zajmuję się fotografowaniem modelek, to niezbyt mam jak przetestować DALL-E pod względem przerabiania własnych fotografii. Próbowałem nawet zdjęć, w których postać miała zasłoniętą większą część twarzy ręką, albo gdzie kapelusz zasłaniał wszystko powyżej ust, ale i tak dostawałem komunikat, o braku możliwości wrzucania zdjęć z twarzami. To dobrze, bo oznacza, że DALL-E mimo to rozumie, co jest na zdjęciu. Dokopałem się więc do fotek motocykli sprzed kilkunastu lat (z etapu tzw. HDR Hole), wybrałem jedną i sprawdziłem jakie warianty zostaną wygenerowane.
Oryginał:

Warianty:

Nie były to zbyt satysfakcjonujące wyniki, więc postanowiłem sprecyzować zmiany. Poprosiłem o slicki i usunięcie rejestracji. Wynik był raczej mizerny:

Być może potrzebuję więcej praktyki z przerabianiem zdjęć w ten sposób (tzn. w wydawaniu komend A.I.), ale póki co mi to nie wychodzi.
Alternatywne, artystyczne A.I.
Podobnym A.I. do DALLE, jest Imagen, tworzone przez Google. Zapowiada się znakomicie, ale póki co nie można go jeszcze testować. Inną, artystyczną sztuczną inteligencją, jest Midjourney, które podbija internet, bo jest wyraźnie tańsze od DALL-E i miało łatwiejszy dostęp do zamkniętej bety.






Od kiedy napisałem pierwszą wersję tego artykułu, zmiany w Midjourney zaszły wręcz przeogromne. Szczególnie w generowaniu postaci.

Wciąż to nie ten poziom co DALL-E, bo postacie są bardziej "plastikowe", a "kreatywność" znacznie mniejsza (polecenia dają mocno powtarzalne rezultaty), ale rozwija się znakomicie.

Następnym A.I. tego typu jest bardzo powolne Disco Diffusion, o którym przez moment było głośno, ale szybko nastała cisza za sprawą dużo szybszego Stable Diffusion, które ma otwarty kod i łatwo go używać na swoim komputerze (chociaż jeśli nie ma się bardzo szybkiej karty graficznej z dużym VRAMem, to o szybkich rezultatach można zapomnieć).
Podsumowanie
DALL-E 2 jak na betę przystało, jest jeszcze niedokończone. Wyniki mają różne błędy, artefakty, niektóre komendy dają kiepskie wyniki i czasami rezultaty są dalekie od oczekiwanych. Jednak bardzo często są świetne, a przez to, że zawsze jest proponowanych kilka opcji, to szanse że chociaż jedna z nich będzie dobra, są bardzo duże. Aczkolwiek od kiedy zmniejszono je z 6 propozycji do 4, to znacznie częściej muszę ponawiać próbę wygenerowania czegoś bardzo dobrego.
Beta ma dużo ograniczeń – o braku nagości i wrzucaniu zdjęć z twarzami już wspomniałem. Postacie będące częścią większego kadru, mają rozmywane twarze. Nie można też generować osób znanych, nie tylko z obawy o naruszenie wizerunku, ale po prostu wiemy jakby się to skończyło. Treści polityczne też są niedozwolone i można generować tylko tematy G rating. Czyli brak przemocy, broni itd. Na szczęście zabronione jest też robienie NFT, a sprzedaż rzeczy wygenerowanych przez DALL-E nie może być bezpośrednia – musi to być część większej całości. Więc nie mogę sprzedać pliku z grafiką, ale mogę ją wydrukować na koszulce i sprzedać tę koszulkę. Ale to wszystko kwestie dotyczące beta-testów. Finalna wersja nie wiadomo kiedy będzie, nie ustalono też jak będzie monetyzowana.
Tutaj można się zapisać na beta testy, a na Twitterze w tym wątku, regularnie wrzucam nowe rzeczy z DALL-E, więc zapraszam do obserwowania mojego profilu 😇.
Nie przegap dodatkowych materiałów!
Zostaw mi swojego maila, a wpiszę cię na listę dot. tylko sztucznej inteligencji. Od czasu napisania tego artykułu Midjourney przeszło ogromną ewolucję. Dlatego nadchodzi artykuł o używaniu Midjourney nie tylko do generowania grafik, ale i do modyfikowania swoich fotografii oraz krótki tutorial video, o pierwszych krokach w tym A.I.
Nadchodzi też publikacja o fotorealizmie w Midjourney. Dodatkowo pokażę na żywo, jak korzystam z A.I. i przygotuję listę najbardziej przydatnych narzędzi, opartych o sztuczną inteligencję. Zostaw maila i dam ci o tym znać.
PS. A tutaj jest mój artykuł o Midjourney v4, które wyszło kilka miesięcy po tym jak napisałem powyższy artykuł.
Aktualizacje
UPDATE 1: Po napisaniu tego artykułu, zostałem wypytany w poniższym odcinku podcastu "Nadgryzieni", o szczegóły tego, jak precyzowałem polecenia dla DALL-E, co daje jakie rezultaty itd. Zaczyna się w 00:14:20:
UPDATE 2 [21.07.2022 Monetyzacja DALL-E 2]: Obecnie beta nie ma już 50 kredytów dziennie, tylko 15 kredytów miesięcznie + 50 na start. Dodatkowe kredyty można wykupić: 115 kredytów kosztuje $15. Każde wygenerowanie to koszt 1 kredytu.
UPDATE 3 [28.07.2022 Więcej materiałów o DALL-E 2]: Odbyłem dwie rozmowy dotyczące sztucznej inteligencji – jedną w Podcaście Niezłe aparaty, na tematy jakie poruszałem w tym wpisie, a drugą z prawnikiem. Kto ma prawa do rzeczy wygenerowanych przez A.I; czy można je kopiować bez zgody itd. O tym wszystkim rozmawiałem z Wojciechem Wawrzakiem. Obie rozmowy znajdują się tutaj.

UPDATE 4 [02.12.2022]: Od dłuższego czasu beta jest otwarta dla wszystkich.
UPDATE 5 [14.12.2022]: Dodałem informacje o tym jak upscalować grafiki za pomocą Gigapixela.
UPDATE 6 [31.12.2022] Aktualizacja dot. możliwości Midjourney v4.