Midjourney AI w 2023 roku – sztuczna inteligencja do generowania grafik. Poradnik, konfiguracja, prompty itd.

Midjourney AI to jedna z najpopularniejszych i najlepszych sztucznych inteligencji, do generowania grafik, która jest jednocześnie zdecydowanie atrakcyjniejsza cenowo od DALL-E 2. W ofercie ma m.in. pakiet bez limitu generowanych grafik i bezpłatny pakiet testowy. W ostatniej wersji (v4) bardzo poprawiono złożone komendy oraz generowanie twarzy, więc każda grafika w tym wpisie jest podpisana promptem (komendą/opisem), użytym do jej zrobienia. Dodatkowo napisałem artykuł kontynuujący ten temat – dotyczy tworzenia fotorealistycznych grafik w Midjourney i jeszcze w styczniu go opublikuję.


Nie przegap dodatkowych materiałów!
Szykuję artykuł o upscalowaniu grafik z A.I; o używaniu Midjourney do modyfikowania swoich fotografii oraz krótki tutorial video, o pierwszych krokach w Midjourney.
Nadchodzi też kontynuacja tego artykułu, rozwijającą temat fotorealizmu w Midjourney. Dodatkowo pokażę na żywo, jak korzystam z A.I. i przygotuję listę najbardziej przydatnych narzędzi, opartych o sztuczną inteligencję. Zostaw poniżej maila i dam ci o tym znać:





W sumie na tę publikację składa się kilkaset grafik i temat jest tylko liźnięty, bo to materiał na książkę, a nie na artykuł. Dlatego uznaję go za część serii, która będzie kontynuowana w formie zarówno tekstowej, jak i filmowej.




Pokażę w tym wpisie jakie komendy się sprawdzają, kiedy wyniki są bardzo generyczne, a kiedy zaczynają być bardziej "kreatywne" oraz jak skonfigurować to narzędzie, żeby mieć najlepsze efekty.

Midjourney v1, v2, v3 i v4
Na start warto pokazać postęp, jaki nastąpił w czterech wersjach Modjourney. Użyłem tej samej komendy, tak prostej, że jest zrozumiała nawet dla najstarszych algorytmów i wygenerowałem grafikę na bazie tego samego "ziarna" (seed). Czyli jeśli milion razy wykonam to polecenie, to milion razy otrzymam taki sam rezultat, a nie za każdym razem inny, jak byłoby normalnie (w v4 różnice zostały całkowicie wyeliminowane, wcześniej były drobe). W efekcie patrzymy na tę samą grafikę, tylko "zinterpretowaną" inaczej, przez różne wersje Midjourney. To trochę jakby zrobić zdjęcie w tym samym momencie, z tego samego miejsca, czterema różnymi aparatami, by móc je porównać. Midjourney z każdym promptem daje nam cztery propozycje, więc pokażę wszystkie:
















Jak widać, do v3 niemożliwym było jakiekolwiek sensowne porównywanie tego do DALL-E 2, ale v4 poczyniło tak duży postęp, że postanowiłem stworzyć ten artykuł. Parametr --seed będzie czasem wracał w moich poleceniach, gdy będę chciał pokazać jaką różnicę robi jakaś jedna konkretna fraza.




Jeśli chce się sprawdzić seed wygenerowanej grafiki, to trzeba na nią najechać i kliknąć ikonę dodawania reakcji, czyli wstawienia emotikony. Niektóre emoty mają w Midjourney różne funkcje, nas teraz interesuje koperta:

Po jej kliknięciu grafika zostanie wysłana do nas w prywatnej wiadomości, razem z seedem:

Midjourney v4 chce być za wszelką cenę ładne
Po wygenerowaniu tysięcy grafik, nie mam żadnych wątpliwości, że Midjourney v4 bardzo stara się robić ładne obrazki, czego o innych A.I. bym na pewno nie powiedział. Co za tym idzie, nawet wpisując bardzo krótką komendę w Midjourney, dostaje się estetycznie wyglądającą grafikę, a więc zupełnie inaczej jak DALL-E 2, gdzie dopiero doprecyzowany prompt, da takie rezultaty.
W DALL-E starałem się określić wszystko – rodzaj kadru, kolorystykę, obiektyw, szczegółowy wygląd postaci itd. W MJ nawet gdy tego nie zrobię, to i tak najpewniej wyjdzie coś dobrze wyglądającego. To sprawia, że Midjourney jest bardzo przyjemne i łatwe w używaniu, nawet jeśli nie do końca potrafi się sprecyzować swoje oczekiwania.


Niestety bardzo cierpi na tym "kreatywność" tego A.I; bo wyniki są dużo bardziej generyczne, mało urozmaicone i po prostu "na jedno kopyto". Co prawda parametr --chaos 100 wpisany na końcu komendy sprawia, że propozycje 4 grafik jakie dostajemy, są bardziej urozmaicone (mniejsza liczba, da mniejsze urozmaicenie), ale i tak czym więcej ilustracji z Midjourney się widziało, tym bardziej wydają się powtarzalne i tym mocniej widać rożnicę w stosunku do DALL-E 2.


Skoro nie ma aż takiego parcia na robienie długich promptów, bo i tak wszystko wygląda ładnie, to wstawiam tutaj obrazki bazujące głównie na krótkich komendach, a o tym jak jak je komplikować, by uzyskiwać dokładniejsze rezultaty, jest rozdział "Komendy określające wygląd grafik".

Brak znaków wodnych i innych oznaczeń
Podobno rekruterzy już teraz otrzymują mnóstwo portfolio sfabrykowanych za pomocą AI, które rzekomo przestawiają prace z 3Ds Maxa, Blendera, Mayi lub nawet same szkice. Grafiki z Midjourney nie są w żaden sposób znaczone, nie mają znaku wodnego jak te z DALL-E 2, a nawet gdyby miały, to usunięcie go i tak byłoby kwestią pojedynczych sekund. Oczywiście prace z Midjourney, udające rendery, są wychwytywane, bo mimo wszystko są dość charakterystyczne i jak zobaczycie tysiące wygenerowanych grafik, to też będziecie widzieć schematy, ale o tym później. Natomiast pod tym względem też poczyniono postępy i podobieństwa są znacznie mniejsze niż kilka miesięcy temu.




Jak tego typu A.I. wpłyną na rynek pracy, do czego będą i już są wykorzystywane itd. tutaj się rozpisywał nie będę, bo wszystko to spisałem w bliźniaczym artykule: DALL-E 2: sztuczna inteligencja tworząca sztukę, grafiki i "zdjęcia" i polecam otworzyć go sobie w osobnej karcie.




Ceny Midjourney
Midjourney ma darmowego triala z 25 grafikami, za $10 miesięcznie można kupić 200 obrazków, a za $30/mc jest pakiet bez limitu i za pierwszym razem to go bardzo polecam, żeby wszytko przetestować. W płatnych pakietach mamy licencję na komercyjne wykorzystanie grafik, a 200 to całkiem sporo, kiedy wie czego się chce i ma się praktykę w używaniu A.I; ale na start to nic. Moje grafiki w Midjourney są liczone w grubych tysiącach, a pewnie w DALL-E 2 zrobiłem nie mniej. Jest jeszcze najwyższy pakiet za $60, dla osób, które potrzebują generować szybko ogromne liczby grafik.








Jak otrzymać dostęp do Midjourney AI
Wystarczy wejść na ich stronę, zapisać się do bety i dodać ich serwer do swojego Discorda (nie trzeba instalować aplikacji, jest też wersja webowa).




Interfejs
To że w ekipie Midjourney nie ma nikogo odpowiedzialnego za design, jest oczywiste od pierwszego wejrzenia. Jak już wspomniałem, wszystko zostało oparte o Discorda, na którym wpisujemy komendy, po czym otrzymujemy 4 niskiej jakości obrazki, a następnie możemy wybrać, które mają zostać powiększone lub jakie byśmy chcieli zobaczyć w innych wariantach. Inaczej mówiąc: wersja alpha pełną gębą.
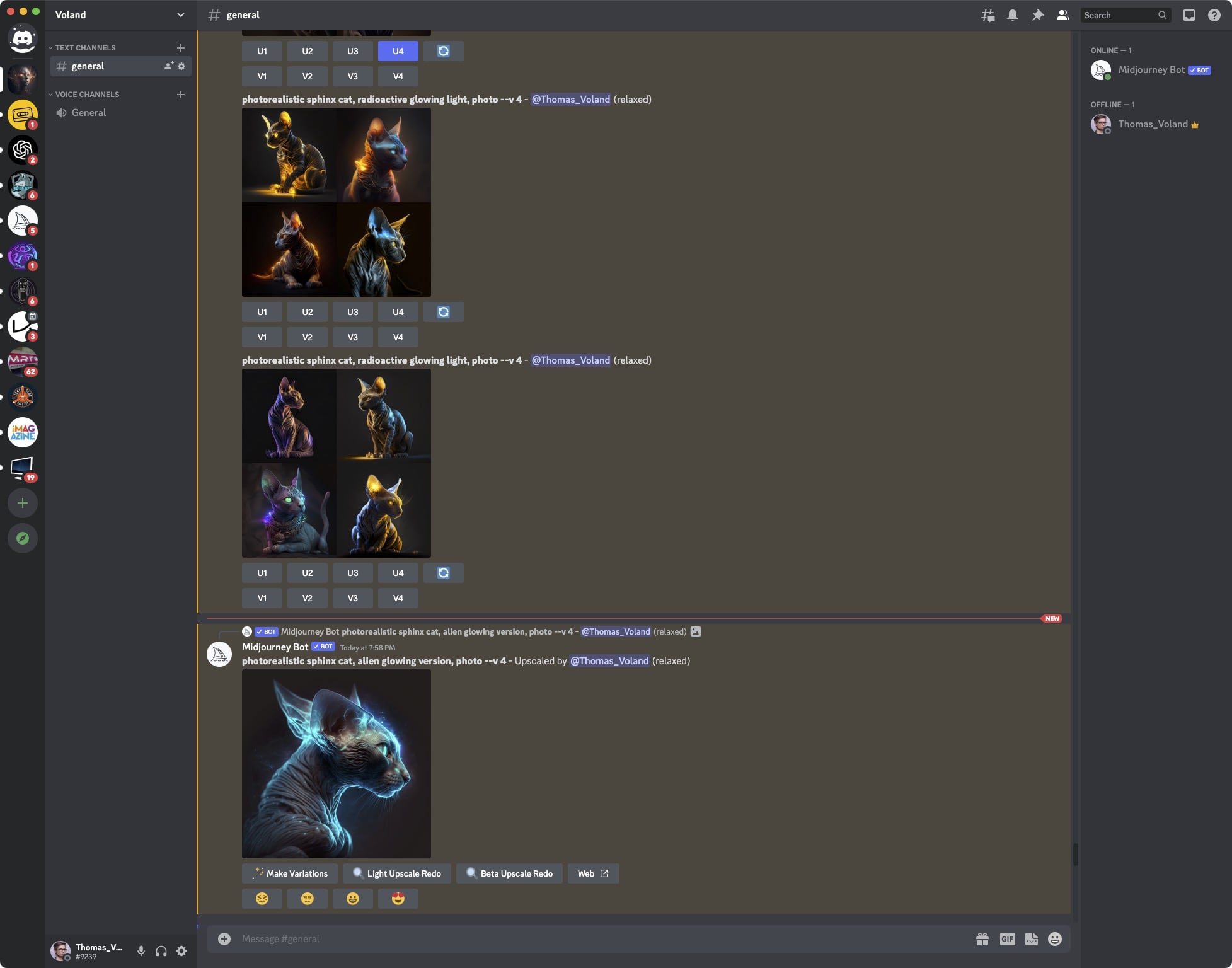
Na szczęście, mimo wszystko Midjourney jest łatwe w obsłudze (i piszę to jako osoba, która Discorda używać nie lubi), bo przez większość czasu ogranicza się do wpisania co chcemy zobaczyć i kliknięcia w przycisk.




Czyli po zaakceptowaniu regulaminu, wpisuje się komendę /imagine na jakimś kanale Midjourney (kanały są z lewej strony w kolumnie, np. #newbies-96, ale w kolejnym rozdzialem opisuję lepszy sposób, niż ten oficjalny), a następnie opis grafiki, jaką chcemy uzyskać (teksty pod wszystkimi grafikami w tym artykule, to właśnie treść komendy jaka została wpisana).
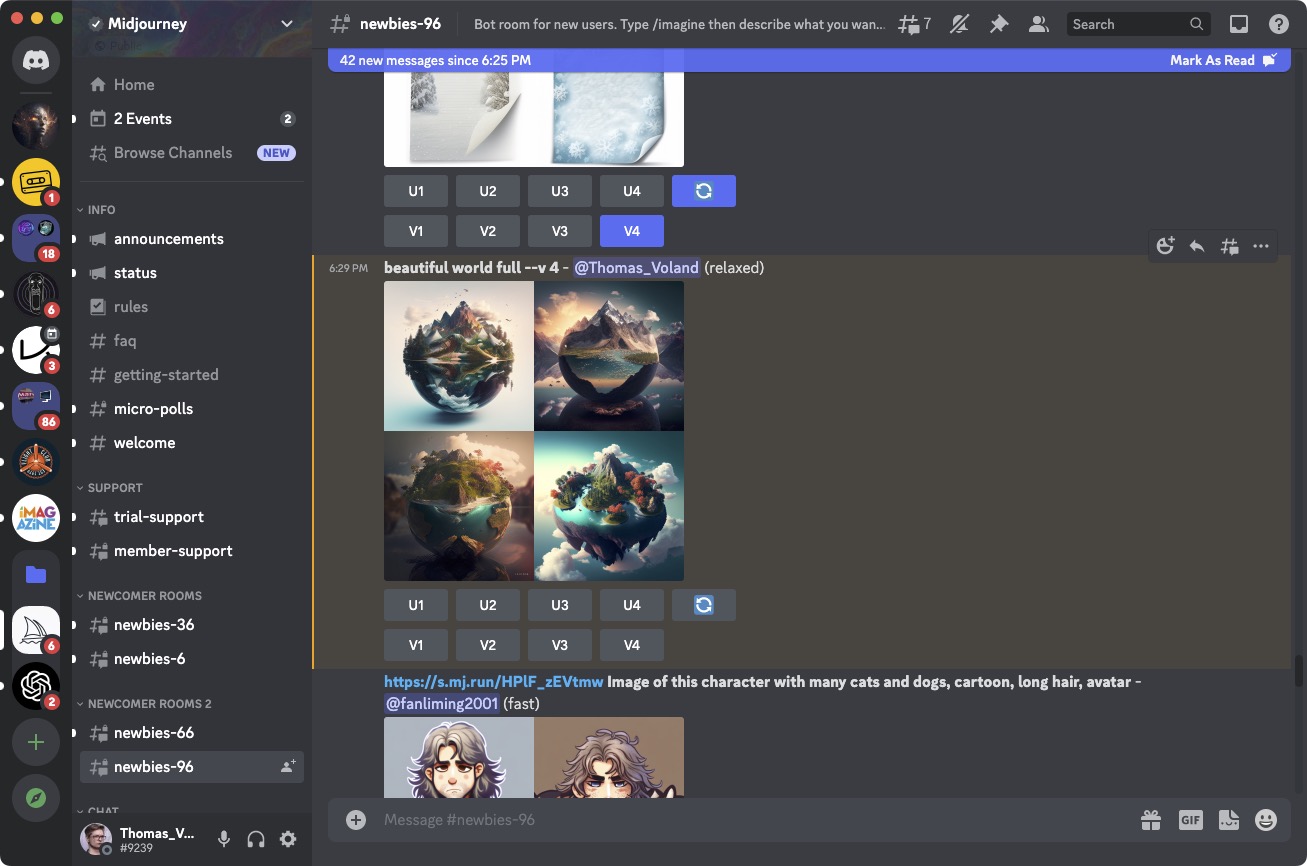
Zresztą po rozpoczęciu pisania, pojawiają się propozycje promptów, więc za drugim razem po wpisaniu samego ukośnika, najpewniej będzie można wcisnąć enter, bo autouzupełnianie załatwi za nas resztę. Ale o komendach napiszę więcej później.





Zazwyczaj wpisuję wiele promptów jeden za drugim, albo kopiuję prompt i wklejam go 5 razy, żeby mieć duży wybór. Po zatwierdzeniu 13 komend, kolejnej nie można wykonać, do póki coś się nie skończy generować. Później przeglądam proponowane grafiki, wybieram te, które chcę upscalować i pobieram na dysk. Jednak gdy uzbiera mi się ich dużo, to zamiast zapisywać je z Discorda, robię to z profilu użytkownika Midjourney dostępnego przez www, czyli ze strony https://www.midjourney.com/app. Kliknięcie w trzy kropki na obrazku i wybranie opcji zapisu działa mi w przeglądarce wielokrotnie szybciej niż na Discordzie, który wymaga potwierdzenia folderu do zapisu i zwleka z wyświetleniem okna dialogowego.
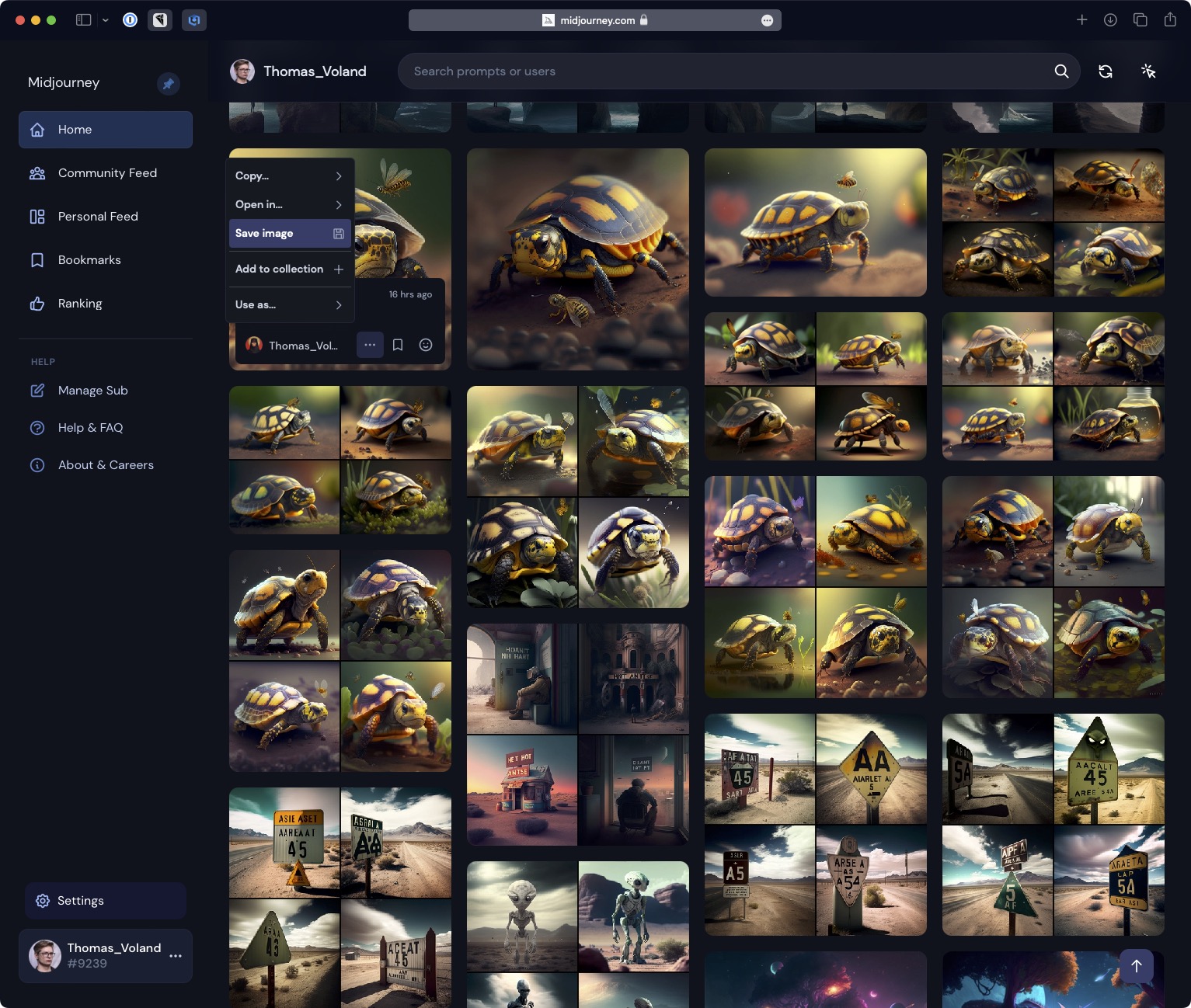
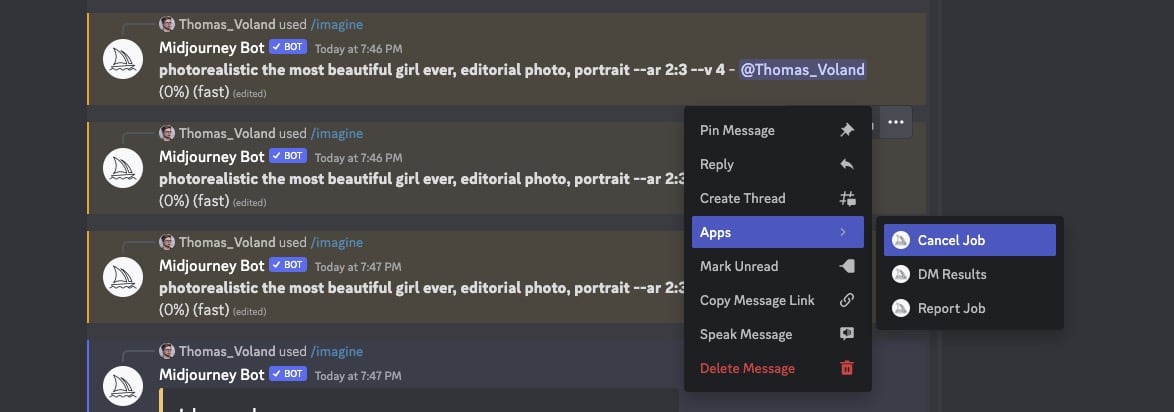
Jednak najwygodniejsza jest opcja zaznaczenia wielu zdjęć i zapisania wszystkich naraz. Natomiast gdy się wpisze prompta źle, albo zapomni się w nim czegoś (u mnie nagminnie są to proporcje), to można anulować zadanie. Wtedy na Discordzie klika się w trzy kropki przy wiadomości > Apps > Cancel Job.
Mamy już zapowiedziane, że Midjourney będzie działać bez Discorda, jako samodzielna strona internetowa, ale póki co jest jak jest.



Jak mieć za darmo tylko dla siebie kanał Midjourney
Normalnie na serwerze Midjourney jest mnóstwo kanałów, na których wszyscy wpisują komendy, każdy je widzi i wyniki również. Przez to poza naszymi grafikami, na timelinie przewija się też setki innych, co zwyczajnie przeszkadza i dopiero wykupienie opcji za $60, daje prywatny kanał.





Dlatego zamiast z tych publicznych kanałów, polecam wysyłać prompty na czacie, czyli po prostu jako prywatne wiadomości do Midjourney, lub stworzyć własny serwer, a następnie dodać do niego bota Midjourney. Zajmuje to kilka sekund, nic dodatkowo nie kosztuje, a dzięki temu mamy własny kanał, wyłącznie ze swoimi grafikami i całość staje się dużo bardziej przejrzysta i przyjemniejsza w obsłudze.
Powiadomienia dotyczące nowych postów, odnoszą się wtedy tylko do naszych grafik, a nie do tych od pozostałych kilkuset tysięcy osób, co dodatkowo umila użytkowanie. Ew. można w wyszukiwarce wpisać swoją nazwę użytkownika, ale więcej zalet mają wcześniejsze rozwiązania. Grafiki wciąż będą publicznie widoczne w profilu użytkownika. Dopiero najdroższy pakiet dodaje komendę /private ukrywającą wszystko, aczkolwiek ekipa Midjourney nawet wtedy ma do nich dostęp.







Ustawienia generowanych grafik
Zanim się zacznie generować grafiki, warto zajrzeć pod komendę /settings. Po jej wpisaniu można wyklikać jak nasze Midjourney ma działać:
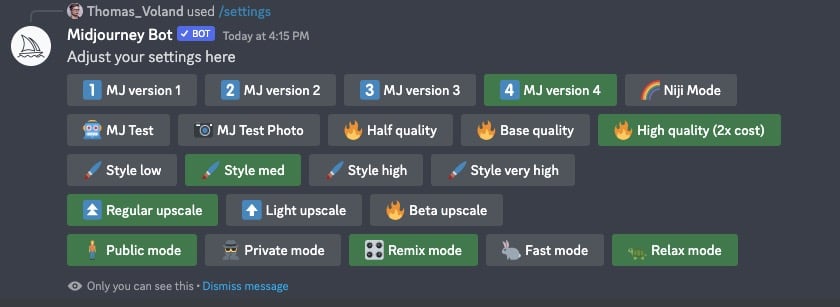
MJ version niemal zawsze polecam używać w najnowszej "stabilnej" wersji, czyli obecnie MJ version 4.
MJ Test oraz MJ Test Photo teoretycznie mogą być lepsze i sprawią, że otrzymamy zupełnie inne rezultaty niż normalnie i co najważniejsze, dużo bardziej zróżnicowane. Test Photo da grafiki bardziej przypominające zdjęcia, często w analogowym klimacie, ale działa mi to na tyle kiepsko, że traktuję to tylko jako ciekawostkę. Różnią się wtedy nawet kadry – często są dziwnie poucinane, trochę jak w DALL-E 2, które lubi zrobić cięcie tuż nad okiem itd.
MJ Test (nie Photo) też tak działa, ale rezultaty są bardziej jak malunki. Wyniki w tych trybach są dużo bardziej zróżnicowane niż normalnie i zapowiadają się dobrze, bo dają nadzieję na kolejny bardzo duży postęp, gdy wyeliminuje się błędy. Jednak w obecnym stanie są zbyt niedopracowane, żebym sobie zawracał nimi głowę.



🌈Niji Mode to tryb dający rezultaty bardziej w stylu anime. Nawet postacie są wtedy defaultowo azjatyckie.




Skoro 🌈Niji mode służy to do rysunkowych treści, to myślę, że nie ma sensu proszenie o fotorealizm, ale oczywiście próbować można:







Wyniki wciąż wydają się stylizowane, ale znacznie bardziej 3D, niż standardowe:







Base quality i High quality dają zdjęcia tej samej rozdzielczości, natomiast czas poświęcony na "obmyślenie" grafiki będzie dłuższy (więc korzystając z trybu "Fast", skasuje nas jak za dwie grafiki). Skutkuje to większą liczbą detali. Jednak prawdę mówiąc, nie widzę między nimi znaczącej różnicy – tam gdzie base quality mnie zawodziło, high quality nie poprawiało sytuacji, a w pozostałych przypadkach Base quality wystarczało.
Style może być ustawione tylko na medium gdy używa aktualnej wersji MJ. Co prawda da się komendą to nieco regulować nawet w v4 i w wersjach beta, ale dużo mniej niż w v3, więc nie zawracałbym sobie tym głowy, chyba że w przyszłości zostanie zmodyfikowane. W uproszczeniu, czym mocniejsze "style", tym bardziej Midjourney starało się upiększyć grafikę, zwracając przy tym mniejszą uwagę na treść prompta.
Regular upscale to opcja, która daje najlepsze rezultaty przy powiększaniu grafik, ale nie osiąga tak wysokich rozdzielczości jak Beta upscale.
Beta upscale robi powiększa znacznie bardziej niż regular (2048x2048 px), ale psuje je przy tym tak bardzo, że nie nadają się do użytku i mam pojęcia, czemu niektórzy jej używają i wręcz polecają w tutorialach. Chyba po prostu robili poradniki na szybko, nie zwracając uwagę na faktyczną jakość, tylko na liczbę przy rozdzielczości, jednak upscaller powinno się porównywać wyłącznie w pełnym rozmiarze, w końcu służy do powiększania. Tak więc na miniaturze takie grafiki czasem wyglądają OK, ale w normalnym rozmiarze nadają się tylko do kosza.


Jest też problem z przejaskrawioną kolorystyką, jakby ktoś dopiero zaczynał z grafiką i nie do końca ogarniał suwaki z nasycenia i kontrastu. Na wielu grafikach nie wygląda źle, ale najgorzej jest z ludźmi, bo skóra wygląda wtedy bardzo nienaturalnie.


Jeśli się chce dużą grafikę, to użycie Regular upscale i powiększenie jej przez zewnętrzne narzędzie, daje nieporównywalnie lepsze rezultaty i obecnie to jedyne sensowne rozwiązanie (ja używam Topaz Gigapixel AI i Photo AI, później pokażę jak sobie radzą). Ekipa Midjourney też jest rozczarowana obecnymi ulepszeniami ich upscallera i zapowiedziała, że zamiast go rozwijać, być może taki zostanie, jeśli Midjourney v5 uda się wyeliminować problemy.


Light scale pominąłem, bo to uproszczona wersja, dla której nie mam zastosowania, ale jeśli chce się ograniczyć detale (np. w szkicach, ilustracjach itd.), to jest to jeden ze sposobów. Inny popularny to normalne upscalowanie, ale z parametrem --stop 80, gdzie liczba może być inna i oznacza ona na ilu procentach proces powiększania ma się zakończyć.


Public mode musi być włączone, jeśli nie ma się pakietu za $60, jednak dla wygody nie ma to znaczenia gdy, się używa Midjourney w taki sposób, jak pokazywałem, ale dla prywatności owszem, bo dopiero wyłączenie Public mode lub użycie komendy /private (również wymagającej $60 pakietu) ukrywa grafiki.
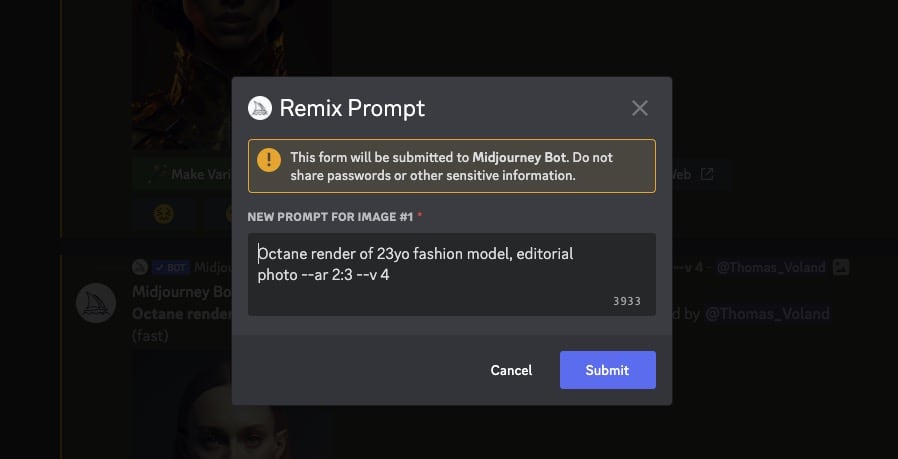
Remix mode pozwala na robienie różnych wariacji grafik z nieco zmienioną komendą, czyli po prostu po kliknięciu np. V1 pojawi się okno z promptem do edycji. Ikony do wariantu pojawiają się niezależnie od tego czy Remix mode jest aktywny, więc nie trzeba kombinować ze sprawdzaniem seeda grafiki i generowaniu na jej podstawie kolejnej.
Fast mode generuje grafiki w trybie priorytetowym, czyli szybciej. W darmowym pakiecie i najtańszym wszystko jest generowane w ten sposób. Natomiast w nielimitowanym pakiecie mamy do dyspozycji ograniczony czas serwera w tym trybie – 15 lub 30 godzin. Można uogólnić, że 1 wygenerowanie grafiki lub upscalowanie, zajmuje 1 minutę GPU. Robienie wariantów jest dużo mniej zasobożerne trzeba ich zrobić ok. 200 by zużyć 1h. Można też generować bez żadnych limitów w trybie Relax mode i jeśli nie generuję mnóstwa grafik "na już", to zazwyczaj ten tryb wystarcza.


Szybkość działania Midjourney
Szybkość A.I. jest bardzo subiektywna i minuta czasu GPU wcale nie znaczy, że po minucie dostaniemy grafikę. Dla użytkownika Disco Diffiusion, Midjourney będzie szybkie jak błyskawica, dla osoby korzystającej z DALL-E 2, będzie powolne lub ekstremalnie powolne, w zależności od obciążenia serwera.




O ile w rozwiązaniu OpenAI, czas na otrzymanie wyniku, jest zawsze bardzo podobny, to w Midjourney nie umiem go określić. Ok. minutę generuje się grafika, ale zanim to nastąpi, często trzeba poczekać na swoją kolej – wówczas w trybie Fast nastąpi ona szybciej niż w Relaxed. Natomiast nigdy nie jest to kwestia 5-10 sekund, jak w DALL-E 2, tylko zawsze znacznie dłużej. Czasem generuję grafiki jedna za drugą, innym razem odechciewa mi się pisać ten artykuł, bo tak długo czekam na Midjourney. Natomiast normalni użytkownicy raczej nie będą tak jak ja, generować tysięcy grafik w tydzień, więc powinni być zadowoleni. Tym bardziej, że mam wrażenie, iż prędkość jest mi ograniczana, gdy generuję dużo grafik pod rząd.




Midjourney nie rozróżnia modeli Jordanów, więc po dłuższych testach poddałem się i przestałem określać ich numerację.




Wielokrotne upscalowanie tego samego
Gdy propozycje czterech grafik zostaną stworzone, to można nawet tylko jedną z nich upscalować wiele razy, zawsze otrzymując nieco inny rezultat. W procesie powiększania, Midjourney dodaje detale i czasem nawet całkiem duże elementy potrafią się różnić. Działa to podobnie do robienia wariantów, bez wprowadzania zmian w prompcie.




Na pierwszy rzut oka to samo, a jak się przyjrzeć, to różni się niemal wszystko – od fryzury, przez urządzenie na głowie, makijaż, plamy na twarzy, ubiór i metal na szyi, na płomieniach w tle kończąc. Poza powyższymi grafikami, wszystkie inne w tym wpisie są odrębnymi obrazkami.
Warianty/Remixy

Jak chwilę wcześniej wspomniałem, poza upscalowaniem grafik (U1, U2, U3, U4), da się stworzyć jej wariant (V1, V2, V3, V4). Pojawia się wtedy okno, w którym można doprecyzować komendę. Jednak w przypadku dążenia do fotorealizmu, warianty mi się niezbyt sprawdzały, bo było na nich wyraźnie więcej deformacji, niż na grafikach generowanych od zera. Mam też wrażenie że małe modyfikacje sprawdzają się lepiej niż dopisywanie długich zdań.




Jak widać, dodanie w prompcie "ultra realistic photo", wcale nie oznacza, że otrzymamy fotorealistyczny rezultat.




Proporcje kadrów
Proporcje generowanych grafik można zdefiniować i zamiast kwadratowych, mieć poziome 3:2 lub pionowe 2:3. Otrzymamy wtedy więcej pikseli na dłuższej krawędzi, a krótsza dalej będzie mieć ich 1024.








Dopisek --ar 2:3 oznacza właśnie aspect ratio 2:3. Większą różnicę robi to np. w architekturze, plenerach itd. Natomiast akurat przy tym prompcie największą zmianą byłoby częste ucinanie części stylizacji.





Takimi grafikami, przypominającymi zdjęcia, zajmuję się w kontynuacji tego artykułu, która wkrótce będzie opublikowana.
Komendy określające wygląd grafik
Całe postacie
W Midjourney jeśli się nie określi kadru, to bardzo często wyjdzie portret, a w wielu komendach wręcz za każdym razem i grafiki z poprzedniego akapitu są tego świetnym przykładem – stworzyłem podobnych setki, otrzymując wyłącznie portrety. Jeśli z jakiegoś powodu tak nie jest, to komenda "portrait" powinna dać właśnie kadr portretowy. Do generowania całych postaci samo dodanie frazy "full body" u mnie się często nie sprawdza. Mam wrażenie, że "full body view" częściej skutkuje całą postacią, ale pozy są często jak u manekina.




Dodanie np. "dancing" wprowadzi mniej sztywne pozy.




Dużo osób do "full body" dodaje jeszcze "wide angle", jednak jak każdy fotograf wie, ten sam kadr z szerokim kątem (wide angle) wyjdzie zupełnie inaczej niż na węższym, bo zupełnie zmieni się perspektywa (ja fotografuję modelki w studio często obiektywem 135 mm, czyli takim jak portrety, a mniej niż 50 mm tylko w bardzo specyficznych sytuacjach). Dodatkowo szeroki kąt to dla Midjourney głównie grafiki z tłem niestudyjnym.


Natomiast czasem Midjourney tak uparcie ucina kadry, że trzeba do prompta dodać ten nieszczęsny szeroki kąt, ale do plenerów często on dobrze pasuje. Chociaż i wtedy potrafi wyjść wiele kadrów uciętych. To cecha wielu artystycznych A.I.
Precyzowanie konkretnych ogniskowych (35 mm, 85 mm itd) w Midjourney, w przeciwieństwie do DALL-E 2, nie daje pożądanych zmian, więc ich nie wpisuję. Poza tym na ogół, całe postacie wychodzą słabo – są często zdeformowane i ujawniają największe wady A.I. obecnej generacji, którym poświęciłem osobny rozdział. Muszę wygenerować nadmiar grafik, żeby wybrać z nich te bez oczywistych problemów.
Waga poleceń
Wielkość znaków nie ma znaczenia, przecinki też prawie nic nie zmienią i są głównie dla nas, żeby prompt wyglądał przejrzyście, ale można też przypisywać wagi do fragmentów poleceń, czyli określać jak bardzo coś jest istotne.




Słoneczny krajobraz będzie zawierał ludzi i latawce, ale ludzie są 3 razy ważniejsi, więc to na nich skupia się kadr, najpewniej będą więksi i na bliższym planie, a to wszystko za sprawą liczb po podwójnym dwukropku:
people::3 kites::1Natomiast jeśli wpisałbym:
people::9 kites::3…to działanie będzie identyczne jak w poprzednim prompcie, bo liczy się stosunek jednej liczby do drugiej. Sama wielkość nie ma znaczenia i 3 do 1 jest tym samym, co 9 do 3. Natomiast jeśli w prompcie byłoby też dużo innych przedmiotów bez dopisanych liczb po dwukropkach, to stanie się to istotne, bo wszystkie nieokreślone rzeczy mają wartość ::1. Różnica między 1 a 2 jest już bardzo duża, więc radzę nie przeginać z liczbami.
Komenda z odwrotnymi wartościami, będzie priorytetyzować latawce:




Natomiast waga może być też ujemna, np. people::-0.5 (ułamki też są dozwolone). Stosuje się to gdy mimo braku czegoś w prompcie, nagminnie pojawia się w dużej liczbie na grafice. Można też użyć wtedy parametru --no, dzięki czemu Midjourney postara się całkiem usunąć daną rzecz z kadru (ale czasem i tak coś zostanie).




Liczba obiektów
Liczby określające rzeczy w kadrze, spisują się całkiem dobrze. Zamiast prosić o zakonnice idące do kościoła, warto określić ich liczbę.

Style
Style artystów
Można definiować style konkretnymi artystami, np. "by Banksy":

To ma ogromne przełożenie na efekt finalny, bo określa mnóstwo rzeczy. W zależności od artysty, może to być kolorystyka, kadrowanie, dobór wyglądu postaci, kontrast, ekspozycja, color grading, dynamika, elementy, które znajdą się w kadrze itd. Style można łączyć:

W przyszłości zaleje nas spraw sądowych, od których będzie zależeć, czy w przyszłości dalej tego typu praktyki będą możliwe, ale obecnie są (tutaj jest nagranie mojej rozmowy z prawnikiem).
Ogólne style
Przeciwieństwem fotorealizmu są grafiki stylizowane i tutaj zdecydowanie najlepiej sprawdzi się metoda opisywana wcześniej oraz na kolejnej stronie, czyli wpisanie nazwiska artysty, ale sformułowania jak digital art, sketch, pixel art, low poly, pen, noir itd. też działają, tylko są dużo bardziej ogólne. One działają raczej zawsze, a np. marker, graffiti, cel shading i wiele innych, Midjourney nie interpretuje poprawnie.






Prawie wszystko może określać styl
Zdjęcia zrobione analogowo wyglądają inaczej niż z najnowocześniejszego sprzętu, a polaroidy tym bardziej. Rok 1990 to inna stylistyka i inny wygląd postaci niż lata '70 lub obecne. Inaczej będą wyglądać pomieszczenia i ubiór ludzi w zależności od kraju itd.




Wszystkie tego typu kwestie drastycznie wpływają na wygląd generowanych grafik, więc warto je określać, jeśli ma się w głowie konkretny rezultat.








Odkryłem, że można też tworzyć grafiki, stylizowane na konkretne gry. Jako maniak poniższych tytułów, bez wahania mogę potwierdzić, że to co wygenerowało Midjourney pasuje doskonale:







Stylizowanie na zrzuty ekranu z gier też jest możliwe:




Także jak już napisałem – prawie wszystkim można określić styl. Już mi się mnożą w głowie pomysły, jak to można wykorzystać na etapie projektowania gier. Na koniec przykład z jeszcze innej beczki i lecimy dalej…







Oświetlenie
Poza typem światła, o którym zaraz się rozpiszę, można doprecyzować jego barwę: najogólniejsze określenia, czyli cold, warm będą pewnie najpopularniejsze.




Teraz czas na typy oświetlenia. Wiele zależy od typu grafiki i tego co na niej jest, ale akurat te poniższe oświetlenia są dość uniwersalne i rzadko zawodzą. Natomiast jeśli zamiast "light" użyje się "lightning", to Midjourney może zrozumieć, że chcemy błyskawicę na grafice, a nie światło w danym klimacie i na tyle często mi się to zdarzało, że "lightning" używam już tylko jak chcę właśnie błyskawicę.
Soft light jest bardzo ogólnym określeniem, oznaczającym miękkie światło, czyli bez ostrych cieni. Nie oznacza to, że będzie niski kontrast i nie będzie czerni (chociaż czasem tak jest), tylko że cienie będą znikać delikatnie jak w pochmurny dzień, a nie natychmiast, jak w słoneczny:


Cinematic light to uniwersalny prompt, gdy nie do końca wiemy, czego chcemy, bo da bardzo różne rezultaty:


Volumetric light to oświetlenie widoczne w atmosferze, czyli światło wychodzi ze źródła i z powodu mgły lub np. kurzu w powietrzu jest widoczne nie tylko na obiektach, ale i w powietrzu. Przy zdjęciach postaci Midjourney niezbyt wie jak to zinterpretować, ale w plenerach jest dobrze:


Sunrise light czyli wschód słońca:


Sunset light czyli zachód słońca:


Golden hour to właściwie to samo co wcześniej – wschód lub zachód słońca. Golden hour uznawany jest za doskonały moment do fotografowania:


God rays to specyficzny efekt wolumetryczny – widoczne promienie światła:


Neon lights to lampy często odbijające mocno się w posadzce i dobrze sprawdzają się w miastach lub zdjęciach ludzi, wraz z określeniem koloru, np. neon blue and red lights i/lub jako światło kontrowe, czyli neon rim light. Często używam takiego światła do cyberpunkowych i robotycznych klimatów. Jednak nawet w leśnej chatce może dać ciekawy efekt:


Colorful light tutaj nazwa mówi wszytko


Dark light to po prostu mroczne oświetlenie, nocne i stłumione:


Warunki atmosferyczne
Opisanie pogody bardzo mocno wpływa na grafikę, bo określa zarówno światło, jak i scenerię:
Fog


Storm


Snow


Sunny


Bazowanie na istniejących grafikach i zdjęciach
Można wkleić link do grafiki lub fotografii i wpisać prompt. Tym sposobem może powstać coś zupełnie nowego, ale jednak powiązanego w jakiś sposób z oryginałem. Oryginał jest traktowany wtedy jako inspiracja.




Widać, że charakterystyczny styl górnej partii ubrania, jest zachowany. Standardowo 20% bazuje na zdjęciu, a 80% na prompcie. Może też wyjść przeróbka, niczym fotomontaż:




Przerabianie grafik, to temat na osobny artykuł i mam go w planach. Natomiast trzeba wiedzieć, że zdjęcie musi być w internecie, a nie na dysku. Najprościej więc przeciągnąć swoją fotkę do okna Midjourney, przez co zostanie załadowana na serwer i stanie się online. Później klikając prawym przyciskiem myszki, można skopiować link i wkleić do kolejnego prompta.
Miksowanie różnych grafik
Do Midjourney można wrzucić linki np. do dwóch grafik, wtedy zostaną one połączone w coś zupełnie nowego. Mogą to być własne zdjęcia/grafiki, albo tak jak w poniższym wypadku, dwie grafiki wygenerowane w Midjourney…


…połączone następnie w coś zupełnie nowego. Wstawiłem linki do obu tych obrazków w Midjourney i bez dodawania jakiejkolwiek komendy, zaakceptowałem. Efekt był taki:


Natomiast zazwyczaj zdjęcia będą tylko początkiem promptu, a tekstem doprecyzuje się co ma być rezultatem.



W zależności od grafik i polecenia, będzie z nich dziedziczony styl, kolorystyka, obiekty itd. Nie chodzi więc tylko o połączenie dwóch obiektów, możliwości są dużo większe.
Największy problem wszystkich A.I.
Przy okazji można zauważyć piętę achillesową, a właściwie dłoń, wszystkich obecnych A.I.

Generalnie nie polecam się przyglądać rękom generowanym przez sztuczną inteligencję, a tym bardziej liczyć palców.




Stopy też są problematyczne, a nawet zęby, ale te na bliskich portretach zazwyczaj wyglądają dobrze, gorzej w szerszych ujęciach (wtedy potrafi ich być za dużo, są różnej szerokości itd), ale tak jest z wszystkimi deformacjami. Na szczęście z zębami jest podobnie jak z tymi od Toma Cruise'a – do póki ktoś wam o tym nie powie, to 40 lat oglądacie filmy w nieświadomości. Jak tylko dowiecie się, że ma zamiast dwóch zębów z przodu, ma jeden, to już o niczym innym nie będziecie w stanie myśleć, gdy kamera robi na niego zbliżenie. Nie ma za co.


Midjourney nie radzi sobie też z napisami umieszczonymi w grafikach. Nie mają one sensu, znaki są pozamieniane miejscami, czasem nawet są to symbole, jakich nie ma w alfabecie.




Mam też wrażenie, że zmiana proporcji kadru na pionowy lub poziomy, nie jest idealna. Są częstsze problemy z generowaniem poprawnego kształtu tęczówek, niż w kwadratowych kadrach.
Rozdzielczość generowanych prac
Tak samo jak w artykule o DALL-E 2, zamieszczałem tutaj oryginalne grafiki prosto z A.I; bez żadnych poprawek w Photoshopie i w standardowym skalowaniu, więc o bardzo niskiej rozdzielczości 1024x1024 pikseli (lub dłuższy bok 1536 px w przypadku kadrów pionowych i poziomych). Aczkolwiek za pomocą Gigapixel AI, mogę bardzo ulepszyć ich jakość. Tutaj przykład wycinka kadru, po upscalowaniu do 4K:
Handsom vampire female after a feast
Mam w przygotowaniu wpis z mnóstwem przykładów przed i po przeskalowaniu gigapixelem, ale musi zaczekać na swoją kolej.
Photorealistic cybernetic angel of darkness came down to earth to destroy all humanity. Darkness, light, destruction, shards, photo
Podsumowanie
Początkowo to była dopiero pierwsza połowa artykułu, ale tę drugą, poświęconą fotorealistycznym grafikom, opublikuję jednak wkrótce, jako osobny artykuł. Jednak już po tej pierwszej części mogę w pełni podsumować swoje wrażenia z Midjourney v4. W porównaniu do poprzednich wersji, jest to krok milowy. Grafiki wyglądają pięknie, są bardzo estetyczne i niesamowicie proste w tworzeniu. Wystarczy wpisać cokolwiek, a wyjdzie fajny obrazek. W połączeniu z nielimitowanym pakietem, uważam, że jest to dużo narzędzie na start niż DALL-E 2 lub Stable Diffusion, o ile przełknie się obsługę przez Discorda.
Jednak wyniki są schematyczne i często widząc grafikę w necie wiem, że pochodzi z Midjourney, jeszcze zanim zerknę w opis. Natomiast i w tym zaszedł bardzo duży postęp między v3, a v4. Grafiki z DALL-E 2 jest ciężej zidentyfikować, są bardziej różnorodne i kreatywne, potrafią wyglądać niemal jak prace senior artysty, a nie juniora. DALL-E 2 rozumie precyzyjniejsze polecenia, co pozwala na ogromną kontrolę, ale przez to jest trudniejsze dla osób początkujących, bo samo z siebie nie dąży do tego, by grafiki były jak najładniejsze. Koniec końców, stosunek jakości do ceny w Midjourney jest świetny i bardzo polecam spróbować, nawet jeśli będzie to tylko demo ograniczone do 25 grafik.
PS.
Pamiętaj, że ten artykuł jest tylko częścią całej serii i najlepsze dopiero nadchodzi. Zostaw swojego maila, a wpiszę cię na moją listę, dotyczącą tylko Sztucznej Inteligencji i podeślę ciekawe materiały. Te najbliższe będą dotyczyć tworzenia fotorealistycznych grafik w Midjourney, upscalowania w super jakości oraz wykorzystywania Midjourney do pracy ze zdjęciami.

Aktualizacja: Fotorealizm
Kwestia, którą w tym artykule tylko liznąłem, to uzyskiwanie grafik, które wyglądają jak zdjęcia, jednak zrobiłem kontynuację poświęconą tylko temu zagadnieniu: zobacz tutaj.
