

Do tej pory rozpoznanie zdjęć, od grafik wykonanych z użyciem A.I; było proste, a przynajmniej niektórzy wciąż tak myśleli. No bo przecież „A.I” nie potrafi robić dłoni”…


… „do tego zęby jakoś dziwnie wyglądają”…

… „i nie da się generować nagości”…

Czy faktycznie, to takie oczywiste, że powyżej są grafiki, a nie fotografie? Dla mnie nie (chociaż może niepotrzebnie kazałem wstawić dym w łazience…). A jeszcze niedawno skuteczność rozpoznawania tworów A.I; miałem doskonałą. Dodam że w rzeczywistości ostrość tych grafik jest znacznie lepsza, ale na blogu używam tylko 1250 px szerokości.

Stworzyłem quiz na Instagramie, w którym można było wskazać co jest zdjęciem ze stocka, a co grafiką – dałem kilka ewidentnych wytworów A.I. dla uśpienia czujności i resztę takich, które uważałem za fotorealistyczne (możesz kliknąć w story z ikoną 🤖 na moim profilu, żeby wyświetlić wyniki).

Wniosek mam jeden – prawie nikt już nie jest w stanie odróżnić zdjęć, od grafik udających fotografie.

Zresztą wiele osób mi doniosło, że strzelało co jest czym. Było to mocno widać po wyrównanych wynikach lub takich, gdzie zdecydowana większość wskazała A.I. jako zdjęcie. Oczywiście niska rozdzielczość Instagrama pomogła, ale to właśnie takiej jakości obrazków używa się w Internecie. W większym rozmiarze łatwiej dopatrzyć się artefaktów.

Nawet nie starałem się poprawić naszyjników na tych portretach – były to pierwsze rezultaty, jakie mi wyszły i tak było z wszystkimi grafikami, jakich użyłem do testu. Natomiast często generowałem wiele wariacji i wybierałem najlepszą. Więcej grafik z IG tutaj wrzucał nie będę, skupię się na tych, które wygenerowałem dopiero przed chwilą.

Grafiki do quizu zrobiłem spontanicznie, w jeden wieczór, po długich miesiącach przerwy od tworzenia realistycznych grafik w AI, bez zgłębiania jakichkolwiek tajników pisania promptów i bez wcześniejszego doświadczenia z alphą v6 Midjourney i Magnific AI. Więcej czasu zeszło mi na przeglądaniu stocka fotograficznego, niż na generowaniu grafik.

Tak więc nie jest to kwestia moich umiejętności lub doświadczenia, bo prompty się pisze inaczej niż kiedyś – jeszcze prościej. Po prostu z odpowiednimi narzędziami dzisiaj każdy może osiągnąć takie rezultaty, podczas gdy półtora roku temu, w zamkniętej becie DALL-E 2, musiałem się o nie postarać starannie skonstruowanym promptem.

A przecież te wszystkie artefakty mógłbym poprawić również za pomocą A.I; bez umiejętności w Photoshopie. Jednak nie robiłem tego. Wszystko tutaj jest bez żadnej dodatkowej obróbki – wygenerowane Midjourney i upscalowane Magnific AI. Aczkolwiek rozdzielczość i bez upscalowania do netu wystarcza i w artykule jej nie wykorzystuję. Używałem tego by dodać fotorealizmu, a nie zyskać dodatkowe piksele.

Profesjonalnie robione sesje i tak niemal zawsze są retuszowane – czasem delikatnie, a niekiedy mocno, często wciąż udając naturalność (dobre sesje biznesowe, portrety itd.).

Innym razem koszmarny kicz Photoshopowy jest niemal standardem (np. w sesjach dziecięcych i mnóstwie zdjęć z bardzo płytką głębią ostrości). To dodatkowo utrudnia rozróżnienie zdjęcia od grafiki. Ta poniższa wygląda dużo naturalniej niż wiele zdjęć:

Fotografie to też zupełne tego przeciwieństwo, jak chociażby niskiej jakości polaroidy.

Póki co pokazywałem tylko grafiki i moim zdaniem dziś nie rozróżnia się ich od zdjęć po ogólnym wyglądzie, tylko po wyszukiwaniu na nich artefaktów. Tylko w związku z tym wystarczy by paznokieć miał niecodzienny kształt/wzór i rezultat jest odwrotny – mianem grafiki zrobionej przez A.I; można okrzyknąć zdjęcie:

Autor fotografii: Công Đức Nguyễn
Powyższa fotografia powstała jeszcze zanim komukolwiek marzyło się generowanie fotorealistycznych grafik. Ale wróćmy do A.I…


Midjourney w wersji v5 i późniejszych mocno poprawiło fotorealizm, a alpha v6 wznosi go na kolejny poziom. Nie jest idealnie, ale coraz lepiej, a liczba artefaktów maleje. Czasem dziwna część ciała jak powyżej, części mechaniczne nie do końca mające sens, to wszystko etap przejściowy.

Teraz można się jeszcze dopatrzeć nieistniejących w realnym świecie modeli samochodów, budynków, zaburzeń w symetrii obiektów.

Jednak to już dzisiaj nie jest przeszkodą, bo wystarczy poświęcić więcej czasu na dopracowanie komendy i wygenerowanie dodatkowych wariantów lub wskazanie miejsc do poprawy.

Jak ktoś chce nas oszukać, to zrobi to, bez potrzeby posiadania jakichkolwiek specjalnych umiejętności.

Czasem z kontekstu i detali łatwo jest stwierdzić, że sytuacja nie miała miejsca.

Tylko, że kiedy coś niezwykłego się wydarzy i A.I. jeszcze trochę się poduczy, to mało kto uwierzy w wizualne dowody, chyba że pomysły na weryfikację oryginalności wejdą w życie i będą nie do złamania. Głos jesteśmy w stanie duplikować A.I. jeszcze lepiej niż grafiki, filmy wciąż kuleją, ale postępy są ogromne.

Wspomniałem o stocku fotograficznym, ale dzisiaj stocki to też grafiki z AI, więc robiąc wspomniany na początku quiz na Instagrama, musiałem uważać, by na pewno wybrać zdjęcia. Na szczęście są opcje filtrowania wyników, a dodatkowo po datach można sprawdzić czy coś dodano jeszcze zanim tego typu A.I. powstały. 1,5 roku temu zapowiedziałem nadchodzącą śmierć fotografii stockowej, teraz w tym przekonaniu się tylko upewniam.

Jesteśmy na podobnym etapie rozwoju A.I, na jakim były telefony komórkowe w czasach gdy do ich noszenia potrzebna była dedykowana walizka. Równe 2 lata temu świat jeszcze nie wiedział o nadchodzącym DALL-E 2 i wszyscy żyli w przekonaniu, że pracownika fizycznego A.I. może zastąpi, ale artystę najpewniej nigdy. Kilka miesięcy później cała branża cocnept-artu wspomagała się A.I. a gdzie jesteśmy po kilkunastu miesiącach widać na przykładach z tego artykułu.

Wspomniałem że używam wersji alpha Midjourney v6, więc jeszcze dodam, że robię to niemal zawsze z parametrem „–style raw”, dla bardziej rzeczywistych rezultatów.
Czym jest Magnific AI
Na początku wspomniałem, że wszystkie grafiki upscalowałem do większej rozdzielczości Magnific AI, żeby dodać im więcej szczegółów.
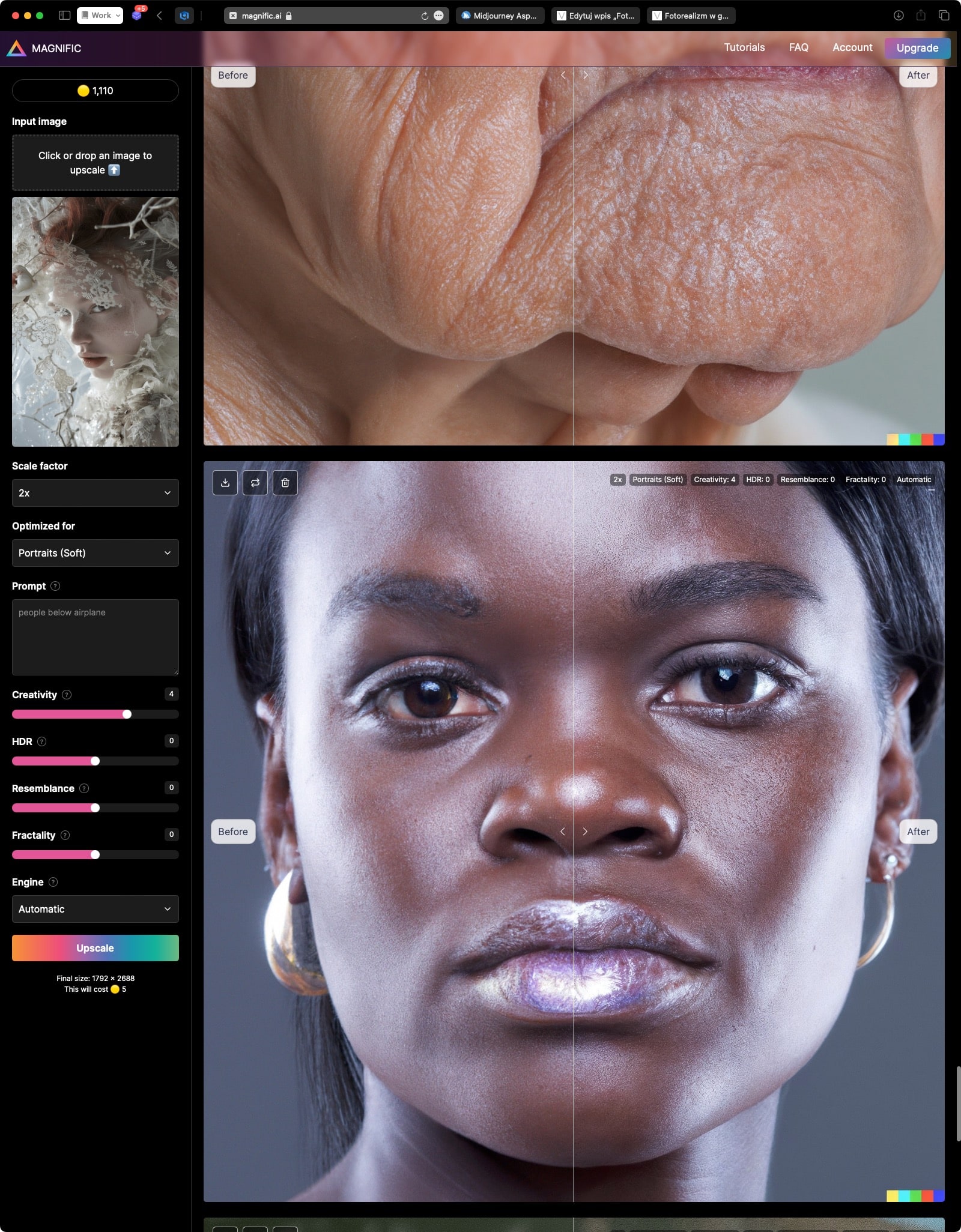
W przeciwieństwie do Gigapixela od Topaz Labs, tutaj dodawane jest dużo więcej detali i finalny obraz różni się od początkowego nie tylko rozdzielczością, ale wieloma innymi elementami.

Głównie operowałem suwakiem „Creativity” w zakresie 0-6, czasem więcej, ale robiły się wtedy dziwne rzeczy (w stylu pojawienia się dodatkowego oka na ręce). Różnica między samym MJ a poprawionym Magnific AI jest znaczna, ale jeszcze większe wrażenie robi gdy użyje się czegoś koszmarnej jakości, jak screenshota ze starej gry:


Dostałem Magnific AI do testów i początkowo dużo używałem opcji upscalowania filmu/fotografii, ale okazało się, że w zdjęciach ludzi opcja „Portrait (soft)” daje dużo lepsze rezultaty, za to z wersji Hard nigdy nie byłem zadowolony.


Upscalowanie do dwukrotnie wyższej rozdzielczości to 5 tokenów przy rozmiarze wyjściowym z Midjourney, czyli ok. 1,2 Mpix. (u mnie często to było 864×1376 px). W najtańszym pakiecie, za $39 dostajemy 2500 tokenów, czyli wg. info na stronie 100 dużych upscalowań lub 200 standardowych, ale jak widać przy niewielkich rozmiarach grafik z Midjourney możemy ich upscalować znacznie więcej. Natomiast w praktyce często trzeba coś upscalować więcej niż raz, testując różne ustawienia. Mimo wszystko nie jest tak drogo jak początkowo zakładałem, ale tanio też nie. Ja dostałem Magnific do testów za darmo, więc lekką ręką klikałem w przycisk upscalowania coraz to nowszych grafik, a finalnie zużyłem dużo mniej tokenów niż początkowo zakładałem. Jakbym kupił najtańszy pakiet, to wciąż miałbym połowę tokenów wolne, a poza tym co widać w artykule, stworzyłem też mnóstwo innych grafik.


Tak że nie jestem już tak krytyczny co do ceny jak byłem początkowo, ale takiego Gigapixela kupuje się raz i używa do woli, ew. po roku dokupuje się dostęp do kolejnych aktualizacji. Jednak przynajmniej póki co, to programy do zupełnie innych celów. Magnific wydaje się świetny do grafik, concept artu i ilustracji, a Gigapixel do zdjęć (ale również do grafik, tyle że takich które po upscalowaniu mają wciąż wyglądać prawie tak samo, tyle że w wyższej rozdzielczości).
O A.I. oraz o upscalowaniu opowiem niedługo więcej na swoim Youtubie.